
Introduction
OctFormer는 Octree 기반의 Transformer 아키텍처를 제안한 모델로, 기존 Transformer의 비효율적인 연산 복잡도(O(N²)) 문제를 해결하고, 대규모 포인트 클라우드에 확장 가능한 구조(스케일 업)를 갖는 것을 목표로 한다.
요약하면, 세 가지 핵심 특징이 있다:
1. Octree Attention 제안
기존 윈도우 어텐션은 정해진 크기의 정육면체 윈도우로 나누기 때문에, 윈도우마다 포함되는 포인트 수가 불균형해 연산 효율이 떨어진다.
반면, OctFormer는 Octree 기반으로 포인트를 정렬하고, 각 윈도우에 동일한 수(K)의 포인트만 포함되도록 하여 균일한 연산 단위를 만들고 GPU 병렬 처리에 유리한 구조를 갖춘다.
2. Dilated Octree Attention 도입
일반 어텐션은 수용 영역(receptive field)이 제한되므로, dilated 윈도우를 사용해 멀리 떨어진 포인트 간 관계도 학습 가능하도록 확장하였다. 이는 윈도우 간 정보 전달 한계를 극복하기 위한 설계로 보인다.
3. 간결한 구현
OctFormer는 PyTorch에서 약 10줄 내외 코드로 구현 가능할 만큼 구조가 단순하다고 한다.
끄적끄적
|
|
|
동작 구조는 간단하다. (표 2) 1) 포인트 입력이 주어지면 지정된 스케일 벡터로 정규화하고, 옥트리 구조로 변환 2) 임베딩 모듈을 사용하여 초기 특징을 다운샘플링하고 고차원 공간으로 project한다. ㄴ 여기서 말하는 초기 특징은 비어 있지 않은 옥트리 노드에 저장된 평균 위치, 색상 등 이라고 한다. 3) 이후 Octformer 블록과 다운샘플링 모듈을 번갈아 적용해서 hierarchical features 생성함. |
|
3.1 Octree Attention 1) Attention - Octree Attention은 스케일된 doc-product attention에 기반을 두고 있다. [Vaswani et al. 2017] - OctFormer에서는 기본적으로 멀티헤드 어텐션을 사용한다. - scanNet같은 대규모 데이터셋은 포인트가 10만개 정도 되는데 기본 어텐션을 쓰면 연산량이 100,000² 이기 때문에 말이 안됨. 그래서 Octformer는 이런 대규모 데이터셋에서도 모델이 처리할 수 있도록 겹치지 않는 로컬 윈도우 내에서만 어텐션을 수행하는 전략을 활용함. - 각 로컬 윈도우 내 포인트 수를 K라고 하면, 연산 복잡도는 O(K² · N/K)로 줄어들고, 결과적으로 N에 대해 선형(linear)이 된다. - 근데 한가지 문제가 있다. 포인트 클라우드는 이미지와 달리 각 윈도우 안에 포함된 포인트들의 개수가 균일하지 않기 때문에 학습에 효율이 떨어진다. 그래서 Octformer는 윈도우 형태가 달라져도 어텐션 결과에 큰 영향을 주지 않는다고 가정하고, 포인트 수를 고정하고 윈도우 형태 고정을 깬다. N : 공간상의 포인트 수 C : 채널수 Wq : query Wk : key Wv : value H : 헤드의 수 K : 윈도우 내 포인트 수 |
 |
2) Octree a) 옥트리 기반으로 분할만 이미지 빨간 점들이 포인트 클라우드 점들이고, 회색 사각형 격자가 옥트리 분할 결과. 2d 형태지만 오른쪽 그림처럼 계속 자식 노드로 분할되는 형태 b) 동일한 깊이에 있는 옥트리 노드들을 기준으로 z-order curve를 적용해 순서 부여 빨간선이 정렬된 경로임. - 옥트리를 사용해서 윈도우 분할을 생성하고, 같은 깊이에 있는 옥트리 노드들을 "shuffle key"를 기준으로 정렬함. ㄴ shuffle key는 x,y,z 정수 좌표를 비트 단위로 만든 것. ㄴ 바꾸는 이유는 공간적으로 가까운 노드를 메모리 상에서도 가깝게 저장하기 위해서 바꿈. |
   |
3) Octree Attetnion c) window Partition 1. 윈도우 분할 - 정렬된 shuffled key를 기반으로, 텐서를 reshaping과 transposing하여 윈도우 분할이 가능함. - 이때 비어 있지 않은 옥트리 노드만 회색으로 표시되며, 해당 노드의 feature들을 순서대로 쌓아 2D 텐서 X ∈ ℝ^{N×C} 생성. 2. 제로 패딩 - 어텐션 연산을 위해서는 feature들을 K개씩 묶은 윈도우 단위(B, K, C)로 구성해야 함. - 하지만 N이 K의 배수가 아닐 수 있으므로, 부족한 만큼 제로 패딩을 통해 N̂을 K의 배수로 맞춤. 3. 마스킹 처리 - 패딩된 제로 벡터는 학습에 영향을 주지 않도록 → 어텐션 연산 시 masking 처리되어 실제 연산에 포함되지 않음. d) Dilated Partition - 그러나 위와 같은 윈도우 어텐션은 계산을 빠르게 하긴 하지만, 수용 영역(receptive field)이 줄어들고, 윈도우 간 정보 전달이 부족해지는 문제가 있다고 한다. 그래서 멀리 떨어진 윈도우들도 함께 묶어서 어텐션을 수행하는 dilated octree attention(확장된 옥트리 어텐션)를 추가로 제안함. 내가 이해하기로는 d 그림처럼 떨어져 있어도 하나의 그룹으로 보고 어텐션을 한다는 거 같다. 그 과정에서 reshape + transpose + flatten 흐름으로 구현함. |
 |
4) Positional Encoding - position encoding은 서로 다른 위치에 정의된 feature을 구별하기 위해 어텐션에 필수적인 요소이다. 일반적으로 relative positional bias 상대 위치 기반 방법이 많이 사용된다. 하지만 octreee attention 구조에서 dilation이 4이상일 경우 모델의 크기가 커지면서 파라미터도 크게 증가해 비효율적이다. 그래서 Conditional Positional Enfcoding(CPE)를 사용했다고 한다. CPE는 현재 feature에 따라 동적으로 위치 정보를 생성하고, Depthwise Convolution를 사용한다고 한다. - 구체적으로는 O-CNN의 옥트리 기반 Depthwise Convolution과 Batch Normalization을 어텐션 모듈 앞에서 위치 인코딩으로 사용한다. (식 3) |
 |
그에 대한 코드는 왼쪽과 같다. # apply conditional positional encoding - CPE 적용 #window partition - 제로 패딩할 개수 계산 - 제로 패딩 추가 - 윈도우 구조로 재구성 후 transfose, flatten # attention mask - 패딩된 포인트는 무시되도록 마스크 생성 # apply attention - 윈도우 단위로 나눈 포인트들에 대해 self-attention을 적용 # reverse window partition - 윈도우 재구성 전 상태로 복원 - 제로 패딩된 포인트는 학습에 반영되지 않도록 마스킹 # remove the padded elements - 최종 출력에서 패딩 부분 제거 |
 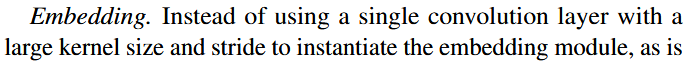  |
3.2 Network Details 다음은 네트워크에 대한 상세 구조이다. (임베딩 모듈, OctFormer 블록, 다운샘플링 모듈) 요약 정리를 우선 하자면, - 임베딩 모듈은 입력 신호를 고차원 특징 공간으로 매핑하며, 공간 해상도를 4배 줄인다. - octformer 블록은 feature을 처리하는데 사용되며, - 다운샘플링 블록은 공간 해상도를 2배 줄이고, 채널 수는 2배 증가시킨다. 단, 마지막 단계에서는 전체 파라미터 수를 줄이기 위해 채널 수를 4C로 고정한다고 한다. 1) Embedding - ViT처럼 큰 커널과 스트라이드를 가진 하나의 컨볼루션 레이어를 사용하는 대신, 작은 커널을 가진 여러 개의 컨볼루션 레이어를 사용한다. - 5개의 옥트리 기반 convolution 모듈을 연속적으로 구성해서 임베딩 모듈로 사용하고, 각 모듈은 octree convolution, BatchNorm, ReLU 함수로 구성 되어있음. |
 |
2) OctFormer Blcok - ocrformer 블록은 옥트리 어텐션, mlp, residual connection으로 구성된다. - MLP는 2개의 FC layer로 구성되고 사이에 GELU 함수가 들어감 |
 |
3) Downsampling - 커널 크기 2, 스트라이드 2의 옥트리 컨볼루션으로 구현 - 이후 BatchNorm 적용되고, 공간 해상도는 절반, 채널 수는 두배로 증가한다. |
  |
segmentation, detection에서는 다음과 같은 성능이 나온다고 한다. |
 position encoding,number,dilation 등 다양한 실험을 진행 |
|
| 마무리 개인생각 - point transformer v3를 읽다가 octformer에 대한 언급이 많아 궁금해서 읽어봤다. - 결론적으로 기존 윈도우 어텐션을 옥트리 기반 어텐션으로 대체한 느낌인데 윈도우 어텐션에 대한 지식이 부족해서 정확히 이해하진 못했다. 완벽하게 이해하려면 vision transformer을 먼저 봐야할듯? - 흥미로웠던건 실험을 하는 큰 매커니즘은 비슷한거같다. ex) position encoding 그리고 데이터 증강에 대한 내용도 있던데 이 부분도 좀 흥미가 생긴다. |
|
'Paper > Point Cloud' 카테고리의 다른 글
| Point-MAE : Masked Autoencoders for Point Cloud Self-supervised Learning (0) | 2025.05.31 |
|---|---|
| Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling (0) | 2025.05.30 |
| Point Transformer V3: Simpler, Faster, Stronger (0) | 2025.05.18 |
| Point Transformer V2: Grouped Vector Attention and Partition-based Pooling (0) | 2025.05.13 |
| Point Transformer (0) | 2025.05.11 |