
Introduction
Point-MAE는 기존 MAE 방식의 장점을 point cloud에 적용시킨 방법론으로, BERT 기반 구조의 한계를 보완하고자 제안되었다. 핵심 아이디어로는 MAE의 랜덤 마스킹, 마스크 토큰의 디코더 이동, 그리고 표준 트랜스포머 기반의 비대칭 인코더-디코더 구조이다. 동작 구조는 입력 포인트 클라우드를 불규칙한 패치로 분할한 뒤, 높은 비율로 무작위 마스킹하고, 마스킹되지 않은 패치들만을 인코더가 처리하여 학습한다. 이후 디코더가 마스크 토큰과 인코더 출력을 함께 받아 마스킹된 포인트를 좌표 공간에서 복원한다.
자세한 내용은 아래에서 다루겠다.
끄적끄적
|
3. Point-MAE 3.1 Point Cloud Masking and Embedding 포인트 클라우드는 이미지처럼 정규적인 패치로 나누기 어렵기 때문에, Point-MAE에서는 다음과 같은 a,b,c 단계로 처리한다. a. Point Patches Generation 익숙한 FPS+KNN으로 patch를 생성하고 마찬가지로 중심점에 대해 normalization 시킨다. b. Masking 포인트 패치들이 겹칠 수 있기 때문에, 개별적으로 마스킹을 적용한다고 한다. 마스킹된 패치들의 집합은 복원 손실 계산 시 gt로 사용 60~80프로 비율이 효과적이었다고 한다. c. Embedding 마스킹된 각 포인트 패치는 공유 가중치를 갖는 학습 가능한 마스크 토큰으로 대체되고, 마스킹되지 않은 포인트 패치는 mini-pointnet으로 학습 가능할 수 있게 한다. 중심점 좌표를 활용해 위치 임베딩도 받아줌. 주의할점은 인코더와 디코더에 각각 별도의 position embedding을 사용한다. |
 |
3.2 Autoencoder's Backbone a. Encoder-decoder Autoencoder 구조는 트랜스포머 백본을 따르고, 인코더에는 마스킹되지 않은 토큰만으로 인코딩하고, 디코터는 인코딩된 토큰과 마스크 토큰을 함께 입력받는다. 추가적으로 위치 정보를 제공하기 위해 위치 임베딩도 입력 마스킹된 토큰을 인코더에서 사용하지 않은 이유는 다음과 같다. 1. 계산비용 절감 높은 마스킹 비율을 사용하기 때문에 마스크 토큰을 디코더로 옮기면 인코더의 입력 토큰 수를 크게 줄일 수있고 이는 트랜스포머의 제곱 복잡도(quadratic complexity)에 따른 계산 비용을 절감할 수 있다. 2. 위치 정보 손실 방지 마스킹된 토큰의 위치 정보를 주게되면 학습이 너무 쉬워져서 깊이 있게 학습하지 못한다. b. Prediction Head 디코더의 출력 결과를 3d 좌표로 변환하는 마지막 단계. 한개의 fc layer를 사용하고 복원 결과를 포인트 패치 형태로 다시 모양 맞추기 위해서 reshape 연산 진행. |
 |
3.3 Reconstruction Target 예측된 포인트 패치 와 정답 포인트 패치가 주어졌을 때, 복원 손실은 Chamfer Distance로 계산된다. 이 수식은 예측된 점들과 실제 점들 간의 거리를 상호 최소화하는 방식으로 평균 제곱 거리 손실을 계산하며, 포인트 클라우드 간의 유사도를 평가하는 대표적인 방법이다. |
 |
4.1 Pre-training Setup 사전 학습에서는 Adamw optimizer 와 cosine learning rate 감소 방식을 사용했다고 한다. |
  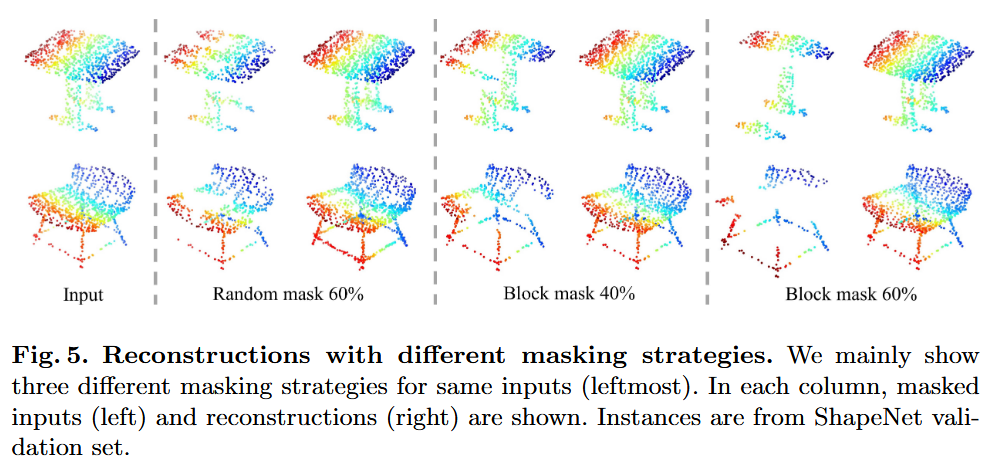 |
총 2가지 Masking 방법을 실험했다고한다. 1. block masking - BERT 2. random masking - MAE 결론적으로 랜덤 마스킹 방식이 더 높은 성능을 냈다고 함. |
 |
앞서 언급했던 마스크 토큰을 인코더 입력에서 디코더 입력으로 이동시켰을때 실험 결과이다. 성능 저하의 이유는 아래와 같다. 인코더 입력에서는 마스크 토큰을 포함한 모든 토큰에 위치 정보(positional embedding)가 포함되어야하는데, 이때 마스크 토큰이 좌표 공간 상에서 복원 대상이 되므로, 위치 정보가 인코더에 조기에 유출되는 문제가 발생한다. 위치 정보가 유출되면 복원 과제가 쉬워지기 때문에, 모델이 충분한 잠재 표현(latent features)을 학습하지 못하게 되고, 그 결과 파인튜닝 성능이 저하된다. |
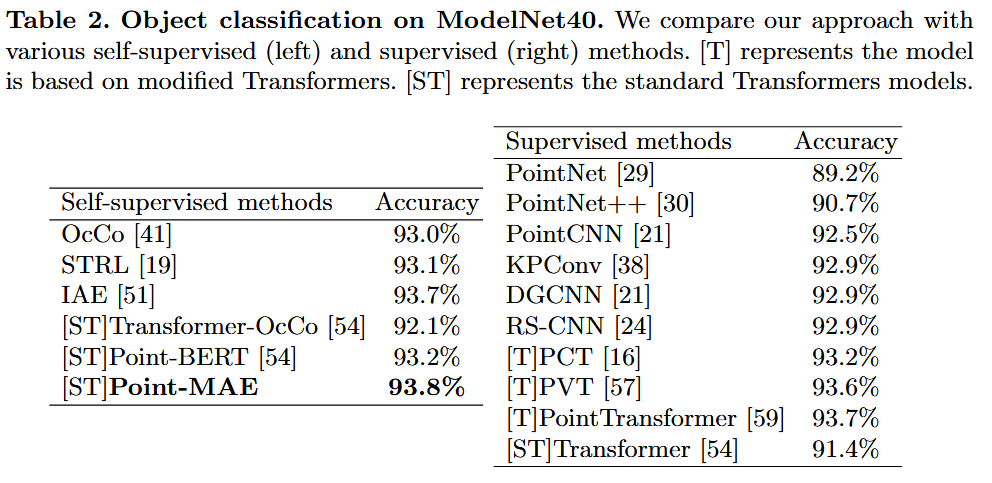 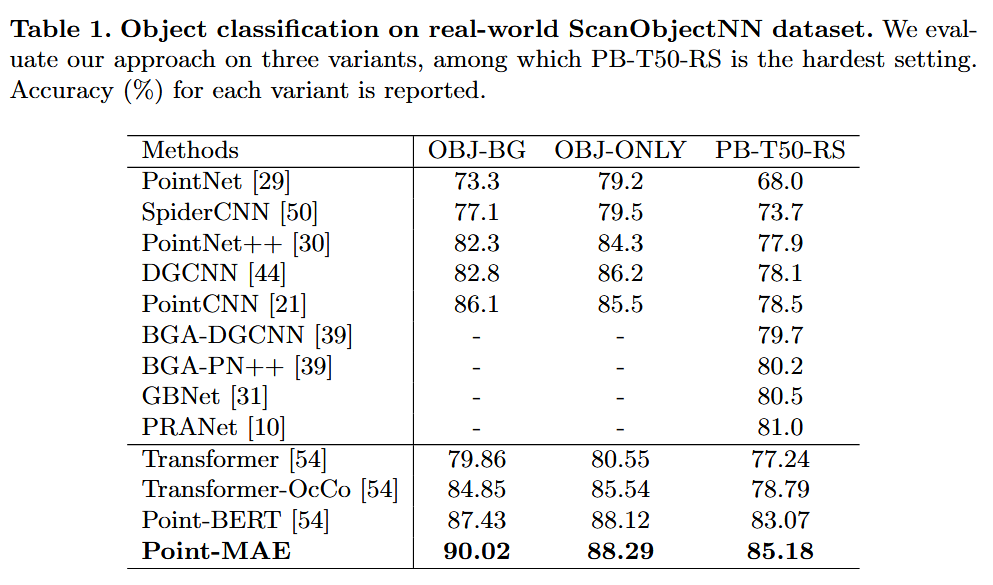 |
classification 성능 |
 |
segmentation 성능 |
| 마무리 개인생각 - Point-BERT의 masking 전략을 보고 다른 전략은 어떤게 있을까 궁금해서 찾게된 방법론, 약 3년전 논문인데 그 동안 더 많은 마스킹 전략이 나왔을 거라 생각한다. 최근 masking전략은 어떤게 있는지 찾아보는 것도 좋을 거 같다. - Point-BERT나 Point-MAE 모두 fps+knn으로 샘플링 했는데 ptv3의 샘플링 방식을 적용하면 성능이 어떨지도 궁금하다. |
|