Introduction
Pointnet++은 기본적으로 Pointnet의 단점을 보완하기 위해 나온 방법이다. 기존 Pointnet은 구조 특성상 점들을 독립적으로 처리하기 때문에 local structure을 파악하지 못한다는 단점이 있다. 이를 보완하기 위해 저자는 입력된 데이터를 중첩된 영역으로 나누고, 그 위에 Pointnet을 반복적으로 적용함으로서 local feature를 학습한다.
지금까지 다른 후속 연구들에서도 계속 사용되고 있는 방법론인 만큼 효과는 보장되었다고 볼 수 있겠다.
끄적끄적
 |
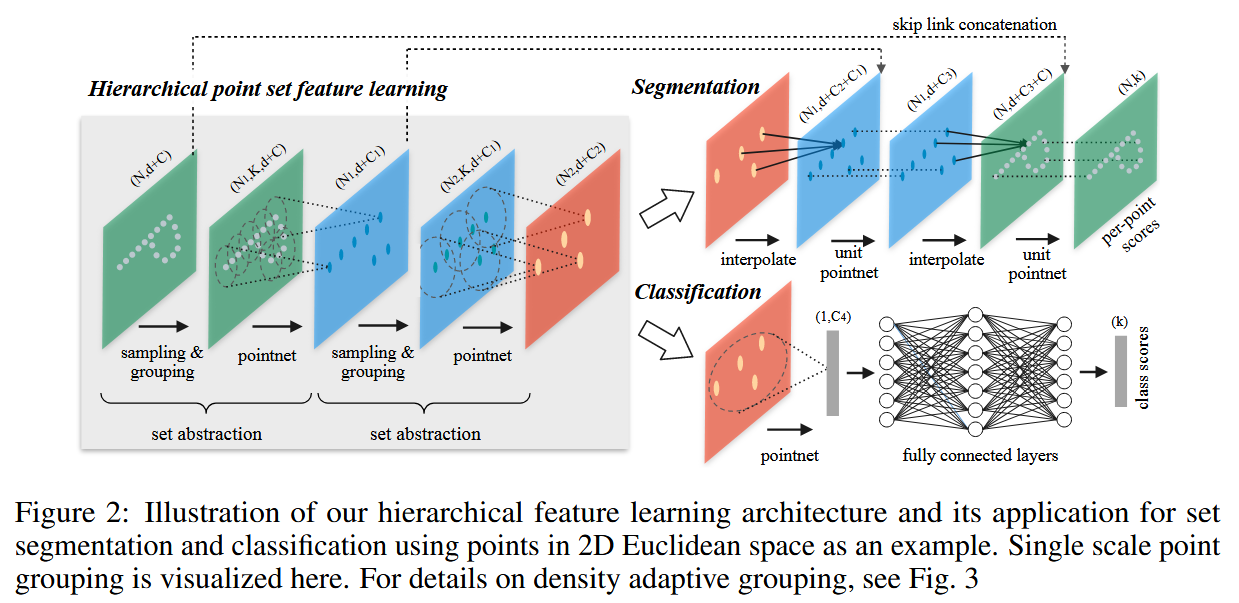
1) Pointnet은 전제 점 집합을 하나로 요약하지만, Pointnet++은 점들을 hierarchical(계층적)으로 그룹화하고 점점 더 큰 local region을 추상화 함. 2) 구조는 여러개의 set abstraction단계를 반복하는 구조임 3) sampling -> grouping -> mini-pointnet |
  |
1) Sampling layer - 중심점을 선택하는 FPS 기법을 사용하여 샘플링을 진행 2) Grouping layer - ball query, knn 방식으로 group을 하는 방법이 있는데 논문은 ball query를 사용 (segmetation처럼 local pattern 인식이 중요한 작업에서는 ball query가 더 일반화에 유리하다고 판단) 3) Pointnet layer - 중심점 기준으로 그룹핑된 점들을 mini-pointnet으로 처리해서 각 local region을 대표하는 feature vactor 출력 |
 |
1) 점들은 일반적으로 고르게 분포되어 있지 않고, 밀도가 지역마다 불균일하다. 2) 밀도가 높은 지역에서는 ball query를 통해 세밀한 구조를 잘 포착할 수 있지만, 이처럼 복잡한 패턴에 익숙해진 모델은 희소한(sparse) 지역의 단순한 패턴조차 과도하게 해석하는 경향이 생긴다. → 결과적으로 과적합이 발생하고, 희소 지역에서 일반화되지 않는 문제가 발생한다. 3) 밀도가 낮은 지역에서는 ball query로 잡힌 영역 안에 점이 거의 없어, 지역 구조를 제대로 파악하기 어렵다. 이로 인해 로컬 feature 학습이 불안정하거나 노이즈에 가까운 왜곡된 정보로 이어진다. 4) 이 문제를 해결하기 위해 MSG,MRG 방법 제안 |
  |
1) MSG 지역마다 밀도가 다르기 때문에, 한 중심점을 기준으로 작은/중간/큰 반경으로 나눠 각기 다른 스케일의 특징을 학습함 학습 중에는 dropout을 통해 입력 포인트를 무작위로 제거해 모델이 다양한 밀도 상황에 대응할 수 있도록 한다.(dropout을 쓰는 이유는 다양한 상황을 가정하는거 같음) → 결과적으로 특징들을 결합하여 robust한 표현 생성. 2) MRG 위에서 언급한 MSG는 모든 중심점에 대해 큰 범위에서 pointnet을 실행하기 떄문에 계산 비용이 너무 큼. 이를 보완하기 위해 지역 밀도가 낮을때와 높을때 방식을 다르게 함. 높을때는 하위 계층에서 추출한 특징을 더 활용하고, 낮을때는 raw포인트 기반 특징을 더 신뢰함. → 결과적으로 계산 효율성과 정밀도 동시 확보 가능 |
 |
1) 위 방법을 적용했을 때 segmentation에서 발생하는 문제와 해결방안에 대해 설명. 2) Segmentation을 수행하기 위해서는 모든 원래 포인트에 대해 label을 예측해야 하지만, set abstraction 계층에서 subsampling이 일어나 포인트 수가 줄어들기 때문에 문제가 발생한다. 3) 이를 해결하기 위해, feature propagation 계층을 활용해 포인트 feature를 원래 포인트 수준으로 복원한다. 구체적으로는 보간(interpolation) → skip connection → unit PointNet 순으로 특징을 전파한다. |
 |
  |
| 마무리 개인생각 1) FPS,KNN 기법으로 점들을 샘플링하고 그룹핑 하는 방식을 이해할 수 있어 좋았다. 2) 그러면 샘플링이나 그룹핑 방식이 FPS,KNN 말고도 다른 방식으로 해볼 수 있지 않을까? |
|
'Paper > Point Cloud' 카테고리의 다른 글
| OctFormer: Octree-based Transformers for 3D Point Clouds (0) | 2025.05.20 |
|---|---|
| Point Transformer V3: Simpler, Faster, Stronger (0) | 2025.05.18 |
| Point Transformer V2: Grouped Vector Attention and Partition-based Pooling (0) | 2025.05.13 |
| Point Transformer (0) | 2025.05.11 |
| PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (0) | 2025.05.09 |